elfvis - binary size treemap viewer
Originally published on Substack.
tl;dr: i built a webpage that shows you where all the flash space in your firmware project has gone.
Elfvis has entered the building:
Originally published on Substack.
tl;dr: i built a webpage that shows you where all the flash space in your firmware project has gone.
Elfvis has entered the building:
I was listening to Dwarkesh's podcast and he referenced some interesting-sounding Jane Street problems. I figured I'd give one a shot.
The problem: you have a neural network's weights, but the layers are scrambled. You need to put Humpty Dumpty back together.
tl;dr: I shared some work on counterfactual analysis of CoTs at a Mech Interp workshop, supported by a Cosmos+FIRE grant. See the technical details.
This year I had the pleasure of engaging in some mechanistic interpretability research. I was specifically curious about the causal structure of chain-of-thought reasoning used by models like OpenAI's o1 or DeepSeek's R1 to solve mathematical problems. What I learned is that these models' chains of thought are deceptively interpretable; that is, at first glance they appear to be thinking in human terms, but counterfactual analysis reveals the real mechanisms of "thought" to be far stranger, with a strong dependence on punctuation and certain expressions that mean to the model something other than what they would mean to a human.
The traditional autoregressive transformer architecture for a language model generates a single token in each forward pass. There is a certain amount of computation that can already happen in that single forward pass: models can add even several digit numbers together without any reasoning tokens or tool calls. However, more complex mathematical problems apparently exceed the computational power available in that single forward pass of the model. Reasoning models extend the compute available by generating a block of thinking tokens before giving the final answer. Through a training regimen pioneered by OpenAI in o1 and published openly by the DeepSeek team with their R1 paper, these models can be trained to do something that looks like reasoning, and it does well on mathematical benchmarks when the problems are similar to problems it has seen in training. As the training data is expanded, presumably with mid-training curricula interleaving mathematical and coding problems, these models are gaining significant utility in automating certain tasks in software engineering and assisted proof solving.
There are however serious shortcomings, one of which is that the models still make mistakes even on problems that we would expect to be well within the capabilities. We see this most starkly when working with a base model that has not been explicitly trained for reasoning, as you can read in my post on errors in DeepSeek V3 Base. (Incidentally, DeepSeek V3 Base may be the last model on which we can run this experiment: models trained after mid-2025 will likely contain examples of reasoning traces in their training data.) Reasoning models seem to make much of the same errors just at a somewhat lower rate, and buried deeper in their longer reasoning traces.
As I was working through some V3 Base traces manually, it occurred to me that it should be possible to find the exact location of the first error in a faulty chain of thought using counterfactual methods similar to what I had worked on some years earlier. I applied Bayesian changepoint detection and active sampling to quickly find the errors in traces of the recent Bogdan & Macar paper, and presented a poster on the topic at NEMI 2025.
At the NEMI poster session I met Eric Bigelow, whose work at Harvard took him down very similar paths, or I should say nearby Forking Paths.
One of Eric's team's findings was that a lot of counterfactual weight was on punctuation marks.
These "forking tokens" such as an opening parenthesis ( were likely to be places where
the probability of successful answer changed precipitously. My work went down only to the
sentence level rather than token level, so I cannot directly compare, but other work
such as this paper by Chauhan et al. provides some
more mechanistic explanation for how these punctuation marks function inside relatively small open-weight models.
I also had the opportunity to have an extended discussion with some folks on the research team at Goodfire who are doing interpretability as a service. Their focus seemed to be mostly on visual and bioinformatics models rather than reasoning, likely because the target market for MIaaS is more around domain-specific models that work in non-text modalities. Nonetheless I was able to rubber duck some things.
I was left with the impression that the line of inquiry I was following is impractical. The causal structure of chains of thought is just as messy as the weights inside the models. Although it appears easy to read, the actual workings are highly complex, inefficient, and alien. These so-called "reasoning" models are the latest search technology, and have their utility, but should always be paired with formal verification, and in cases where this is not possible, there is a great risk of biasing human readers with convincing-sounding model outputs.
I do believe that mech interp techniques can and should be applied to studying structure in CoTs, but this is not going to be easy, it just looks that way because the "thoughts" appear to be in English. (I am morbidly curious what the CoT would look like after applying strong optimization pressure to shorten the CoT while maintaining performance. Would RL/GRPO be sufficient to develop a shorthand language?)
Chris Merck (chrismerck@gmail.com) -- 2nd North East Mechanistic Interpretability Workshop, August 22, 2025, Northeastern University, Boston
Recent advances in chain-of-thought reasoning allow large language models (LLMs) to solve mathematical problems that are beyond the computational power of a single forward pass. This suggests the existence of learned mechanisms operating at the level of reasoning steps in the chain of thought (CoT), yet few techniques exist for identifying these mechanisms. Furthermore, chains of thought can be deceptively interpretable, resembling human internal monologues closely enough that we risk being misled about their causal structure, heightening the need for rigorous interpretability methods. In this work in progress, we develop an algorithm for locating reasoning errors in incorrect base solutions via targeted resampling. This exploration should improve our understanding of chain-of-thought reasoning, particularly how it goes wrong, allowing us to more safely and efficiently operate reasoning models.
One frame through which to interpret reasoning traces is to treat them as the work of a math student, with the researcher as tutor. Correct answers to unguessable problems may be rewarded without inspecting the work, while the incorrect solutions are more interesting: the tutor scans for the first mistake and circles in red pen, leaving a helpful comment. We aim ultimately to automate this process, with this poster presenting some of the elements of work in progress. We see this work as part of a broad effort to take advantage of the present opportunity for CoT monitoring and interpretability (Korbak et al., 2025) and an application of counterfactual techniques from physical systems (Merck & Kleinberg, 2016).
Foundational Work. In their recent groundbreaking preprint, Bogdan et al. (2025) employ several techniques for finding causal structure among the sentences of a CoT reasoning trace, cross-validating counterfactual sampling against attention tracing and masking. They develop the math-rollouts dataset, containing 10 incorrect base solutions to problems from the MATH dataset as generated by DeepSeek R1-Distill Qwen-14B (DeepSeek, 2025), selected for intermediate difficulty (having between a 25% and 75% probability of being solved correctly). The dataset also contains 100 rollouts for each sentence in each reasoning trace, allowing us to explore the probability trajectory and counterfactual scenarios.
Although math-rollouts provides a useful starting point, we would like to eventually scale up to using state-of-the-art reasoning models where exhaustively generating many rollouts for each sentence would be prohibitively expensive. So we apply an active sampling algorithm to efficiently find the sentence containing the most prominent error, termed a changepoint after Adams & MacKay (2007), resulting in a ~100X reduction in the number of rollouts required, at least when the trace contains a clear error.
We propose a Bernoulli process model with a single changepoint τ at which the probability of a correct solution drops from p₁ to p₂:
Bayesian Inference. We maintain a posterior distribution over changepoint locations τ ∈ {1, …, T} using a uniform prior. For each hypothesis τ, we model the probabilities with Beta priors: p₁ ~ Beta(2, 2), reflecting our belief that the initial probability lies between approximately 25% and 75%, and p₂ ~ Beta(1, 19), a strong prior on a low chance of recovery.
Active Sampling. We select the next sample location with replacement to maximize expected information gain about the changepoint location:
where H(τ) is the entropy of the current posterior over changepoint locations and y_t ∈ {0, 1} is the correctness of the hypothetical resampled rollout. This strategy efficiently focuses sampling around the uncertain changepoint region.
Probability Trajectories. With the choice of a strong prior on p₂, we find that the algorithm tends to find reasonable changepoints with just 100 rollouts.
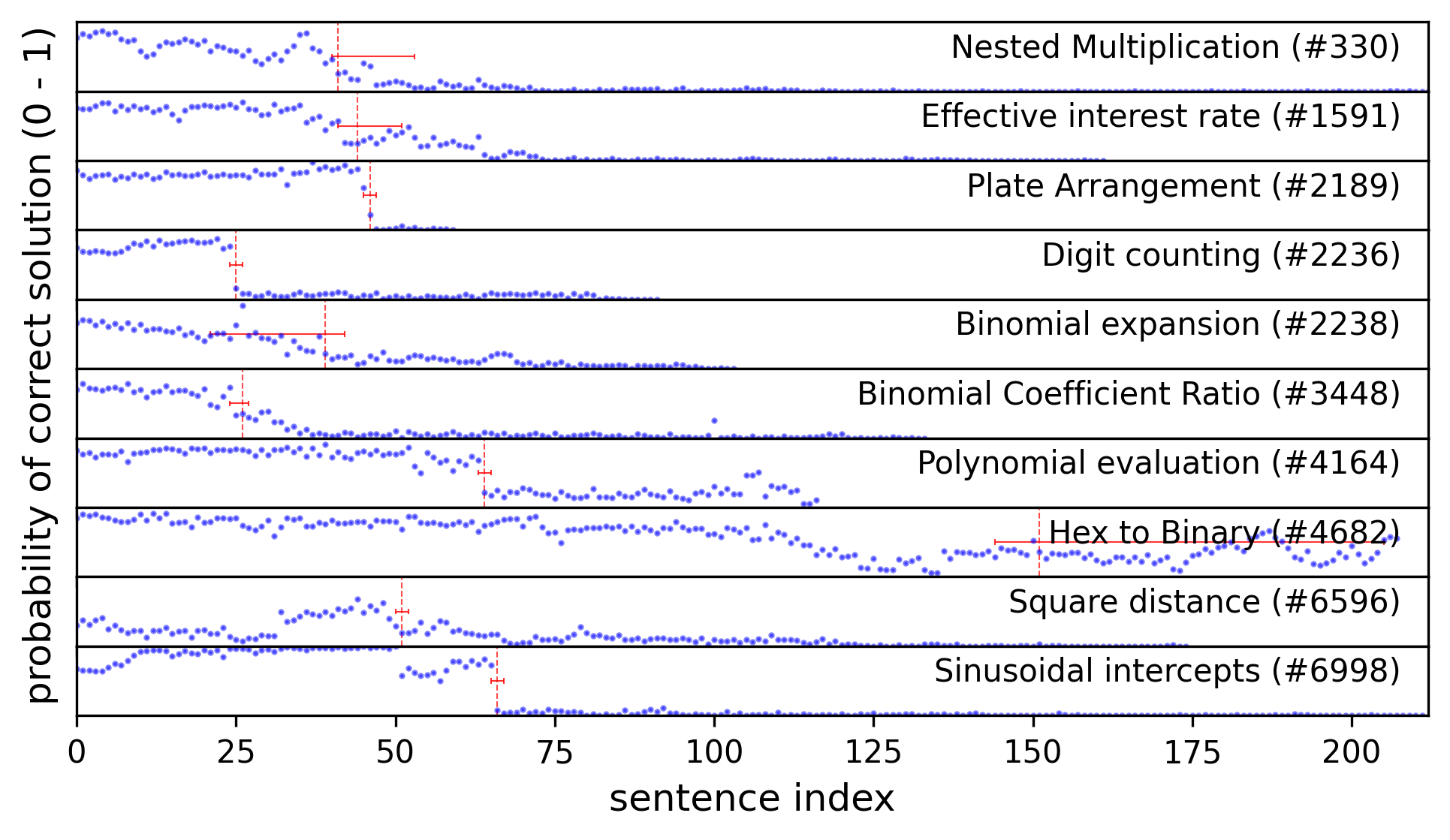
We now examine and discuss selected failures based on the change in answer distribution at the changepoint and a reading of the trace.
Nested Multiplication (#330) — wrong base case in recurrence relation
Wait, wait, no. Let me think. Wait, in the original expression, each time it's 3(1 + ...). So, actually, each level is 3(1 + previous level). So, maybe I should approach it as a recursive computation.
The trace was on the right track—only two computations away from the correct answer. But when the model used the ellipsis (...), many rollouts failed to converge to a boxed answer, recursing until the token limit. The base solution does converge, and fails due to an error in the base case of 4 instead of 0 or 12. Although visually the probability trajectory does seem to contain a clear changepoint, the identified sentence is in fact by inspection the first introduction of this mistake that persists into the incorrect solution.
Now we examine the starkest failure in the Digit Counting problem:
Digit Counting (#2236) — non sequitur
The ones digits here are 1–8, so 4 doesn't appear in the units place in this partial set.
Here the model makes a statement that is obviously false to us, but is generated with approximately a 25% probability at this step. To better understand the structure of this failure, we collect all 100 rollouts resampled at this changepoint sentence and visualize them in a dendrogram. Following Bogdan et al. (2025), we join rollouts if the sentence embeddings have cosine similarity greater than the median similarity between all sentence pairs (0.8).
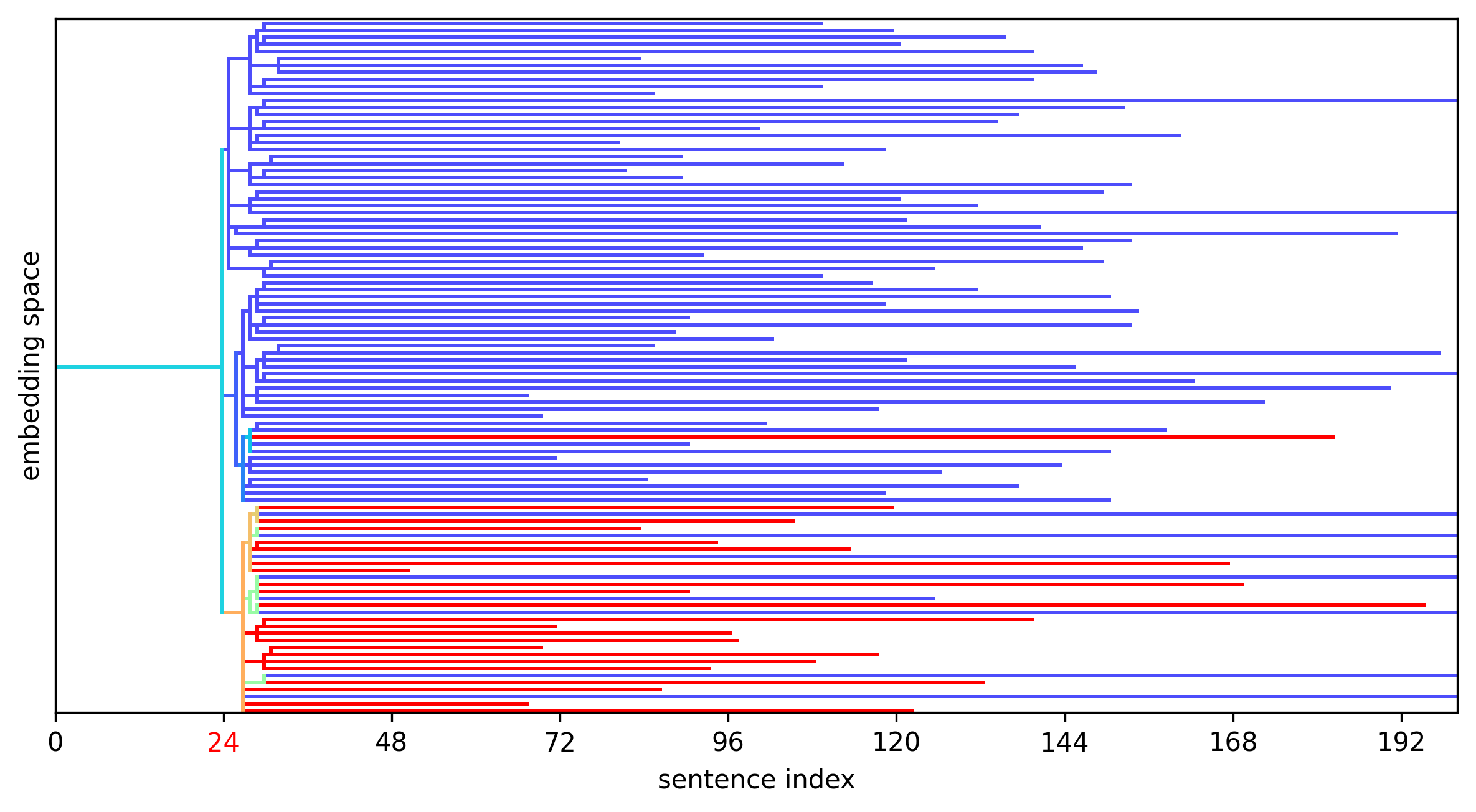
Finally, we examine a case where there is no clear changepoint. Inspecting the the model's solution summary, we find that the model was quite knowingly vacillating between two possible interpretations of the problem:
Hex to Binary (#4682) — trick question
While converting each hexadecimal digit to 4 bits results in a 20-bit binary number, the minimal number of bits required to represent the number 419,430₁₀ without leading zeros is 19.
However, since the problem asks for the number of bits when the hexadecimal number is written in binary, and considering that each hexadecimal digit is typically converted to 4 bits, the correct answer is 20 bits.
Although we prefer to investigate reasoning errors in a counterfactual context, there is a body of existing work that studies errors in chain-of-thought prompting within and beyond mathematical reasoning (Lightman et al., 2023; Tyen et al., 2024), which also examines reasoning structure beyond the influence on accuracy (Xia et al., 2025).
As we saw with the trick question, the failure of these models to deliver mundane utility often stems from issues interpreting the user's prompt rather than logical errors within the chain of thought. The relationship of user intent and model interpretation can be fully formalized (Wu et al., 2022) for mathematical problems. The broader problem of prompt interpretation is of high importance to alignment, especially as models become capable of achieving more work with a single operator instruction.
The rollouts in math-rollouts are drawn from a relatively small 14B model distilled from a larger one (DeepSeek R1 671B). It is possible that reasoning failures in stronger models are qualitatively different, or that the structure of the reasoning behavior differs after distillation. The changepoint detector introduced here is intended to facilitate testing on larger models.
The changepoint model assumes a single error. However, realistic chains of thought may contain multiple errors and backtracking leading to a more complex probability trajectory. It is possible to develop a changepoint detector for these more complex structures, but validation requires much more than the 10 examples available in the math-rollouts dataset.
In particular, the case of no clear changepoint is important to avoid spurious error detections. The algorithm could be updated to track confidence in a null hypothesis.
State-of-the-art reasoning models and agents use parallel execution and subagents (subroutines with chains of thought that are not fully attended to by the top-level agent such as in Anthropic, 2025). Investigating failure modes of these new architechtures is a challenge due to their complexity, however it would appear that the Bogdan et al. (2025) methods could be adapted. Active sampling may be of even greater importance as the compute per rollout increases.
I am grateful for discussions of this work with Anuj Apte. This work is generously supported by a grant from the Cosmos Institute (https://cosmos-institute.org/) and the Foundation for Individual Rights and Expression (FIRE) (https://www.thefire.org/).
Wherein we observe arithmatic errors, infinite loops, handwaving, and wishful thinking. -- Coursework for Frontier Language Models (Summer 2025, Fractal U).
In this post, I manually analyze specific reasoning failures of DeepSeek V3 Base (1). Why the base model? Because if we are to understand how reasoning emerges during RL, we should start by studying the nacent reasoning capabilities of the base models that are the starting point for the likes of R1 (2) and presumably o3, and how failures are avoided. The next post will explore reasoning failures in the R1 model.
We will investigate a simple verifiable math problem for which the base model solves ~75% of the time, and which R1 always solves. This way we can see some of the failures which GRPO RL is able to optimize away.
For the purposes of this post I use a math problem of a kind likely used (1) to train R1, a 3x3 linear system of equations:
This problem is hard enough that we observe frequent and varied failures in V3 Base, but easy enough that perfect performance is achieved by R1.
I use the exact prompt template given in the DeepSeek R1 paper:
A conversation between User and Assistant. The user asks a question, and the Assistant solves it. The assistant first thinks about the reasoning process in the mind and then provides the user with the answer. The reasoning process and answer are enclosed within
<think></think>and<answer></answer>tags, respectively, i.e.,<think>reasoning process here</think><answer>answer here</answer>. User:{problem}. Assistant:
And then in this post I'm using just this problem:
Solve the system of equations: \(4x -3y +6z = 6\), \(-3x +4y +5z = 5\), \(3x +9y -7z = -7\). Give your solution as a JSON array of integers.
I ran the above prompt a number of times and sampled several of the failure cases below with commentary.
Sometimes V3 Base will describe how to solve the problem rather than actually solving it. I hypothesize that in the handwaving example below, the failure is mediated by the use of the auxiliary verbs can and will.
To solve the system of equations, we can use the method of substitution or elimination. Here, we will use the method of elimination. First, we will eliminate the variable x from the first and second equations. To do this, we will multiply the first equation by 3 and the second equation by 4, and then add the two equations together. This will give us a new equation with only y and z. Next, we will eliminate the variable x from the first and third equations. To do this, we will multiply the first equation by 3 and the third equation by 4, and then subtract the two equations. This will give us another new equation with only y and z. Now, we have two equations with only y and z. We can solve these two equations simultaneously to find the values of y and z. Once we have the values of y and z, we can substitute them into any of the original equations to find the value of x. Finally, we will have the values of x, y, and z, which we can represent as a JSON array [x, y, z].
This would be a great preliminary plan, but the model did not actually work through the computation steps, and so it then gives the final answer:
[1, 2, 3]
This looks like an example rather than a guess. This is akin to behavior I've seen from OpenAI models where rather than returing a functional program safisying my request, they return an "example" of how I could do it.
It is well-known that base models tend to end up in repeating patterns. In the completion below, we see such a repeating sequence emerge, but looking closely we can see that an arithmetic error occurred prior: in simplifying \(\frac{45}{4}\frac{38}{7}\), the model eliminated the factor of 2 from the nominator (yielding \(45 * 38 / 2 = 855\)) but then did not eliminate the factor from the denominator (\(4 * 7 = 28\) rather than \(4 * 7 / 2 = 14\)).
<think>To solve the system of equations, we can use the method of elimination or substitution. However, since the coefficients of the variables are not the same in all equations, it might be easier to use the method of substitution. First, we can solve the first equation for x: \(4x = 3y - 6z + 6\) \(x = \frac{3y - 6z + 6}{4}\) Next, we can substitute this expression for x into the second and third equations: \(-3(\frac{3y - 6z + 6}{4}) + 4y + 5z = 5\) \(3(\frac{3y - 6z + 6}{4}) + 9y - 7z = -7\) Simplifying these equations, we get: \(-\frac{9}{4}y + \frac{9}{2}z - \frac{9}{2} + 4y + 5z = 5\) \(\frac{9}{4}y - \frac{9}{2}z + \frac{9}{2} + 9y - 7z = -7\) Combining like terms, we get: \(\frac{7}{4}y + \frac{19}{2}z = \frac{19}{2}\) \(\frac{45}{4}y - \frac{23}{2}z = -\frac{23}{2}\) Now, we can solve the first equation for y: \(\frac{7}{4}y = \frac{19}{2} - \frac{19}{2}z\) \(y = \frac{38}{7} - \frac{38}{7}z\) Substituting this expression for y into the second equation, we get: \(\frac{45}{4}(\frac{38}{7} - \frac{38}{7}z) - \frac{23}{2}z = -\frac{23}{2}\) Simplifying this equation, we get: \(\frac{855}{\color{red}{28}} - \frac{855}{28}z - \frac{23}{2}z = -\frac{23}{2}\) Combining like terms, we get: \(-\frac {855}{28}z - \frac{23}{2}z = -\frac{23}{2} - \frac{855}{28}\) \(\color{red}{-\frac{855}{28}z - \frac{23}{2}z = -\frac{23}{2} - \frac{855}{28}}\) \(-\frac{855}{28}z - \frac{23}{2}z = -\frac{23}{2} - \frac{855}{28}\) \(-\frac{855}{28}z - \frac{23}{2}z = -\frac{23}{2} - \frac{855}{28}\) \(-\frac{855}{28}z - \frac{23}{2 }z = -\frac{23}{2} - \frac{855}{28}\) \(-\frac{855}{28}z - \frac{23}{2}z = -\frac{23}{2} - \frac{855}{28}\) \(-\frac{855}{28}z - \frac{23}{2}z = -\frac{23}{2} - \frac{855}{28}\)
Lastly, I see a case of what I'll call wishful thinking. V3 Base suceeds at eliminating \(x\) in the first step, but then it tries to eliminate \(y\) in the same way, neglecting that a multiplication of one equation by \(6\) is required in order to achieve elimination.
Presumably the model at this point had a choice whether to actually do the correct computation, leading to an unintended result where \(y\) was not in fact eliminated, or to copy the pattern from the first step even though the computation is wrong. It chooses the latter, which though of course reduces to statitical pattern matching, has the appearance of wishful thinking.
<think>To solve the system of equations, we can use the method of elimination or substitution. However, since the equations are already in a form that allows for easy elimination, we will use that method. First, we will eliminate \(x\) from the second and third equations by adding the first equation to the second and third equations. This gives us the system of equations: \(4x -3y +6z = 6\), \(y +11z = 11\), \(6y -z = -1\). Next, we will eliminate \(y\) from the third equation by adding the second equation to the third equation. This gives us the system of equations: \(4x -3y +6z = 6\), \(y +11z = 11\), \(\color{red}{10z = 10}\). Finally, we can solve for \(z\) by dividing both sides of the third equation by 10. This gives us \(z = 1\). Substituting this value of \(z\) into the second equation, we can solve for \(y\). This gives us \(y = 0\). Substituting these values of \(y\) and \(z\) into the first equation, we can solve for \(x\). This gives us \(x = 1\). Therefore, the solution to the system of equations is \(x = 1\), \(y = 0\), \(z = 1\).</think><answer>[1, 0, 1]
I see two directions to take this exploration:
Explore reasoning failures in a reasoning model (R1): does it make the same mistakes only less often? Or does it fail in new ways? This will require harder math problems.
Automate the discovery of the location of the reasoning failure in the chain of thought. One way to do this could be to look at the probability of success as a function of position in a particulary faulty output. I expect that, at least in the case of arithmatic errors, we could automatically discover the exact token at which the error occured, but this does require a lot of inference. I'd like to explore statictical and heuristic methods for efficiently deriving failure explainations.
Wherein I implement a toy model of feature superposition by hand in C as a remedial exercise, and create a video showing the model learning a suboptimal representation.
In the unlikely scenario where all of this makes total sense and you feel like you're ready to make contributions, [...]
- Scott Alexander Nov 2023
In this post, I will manually reproduce the intro figure from Toy Models of Superposition without using anything but the C standard library, so as not to hide any of the details. The paper comes with a PyTorch implementation, but autograds do so much work I feel I need to earn the right to use them by working out the toy model math and code myself.
The basic result is this little animation showing how the model learns the pentagonal representation from the paper's intro:
First off, we need to generate the synthetic data. We want samples with dimension \(n=5\), where features are sparse (being non-zero with probability \(1 - S\)) and uniformly distributed on the unit interval when they do appear, which we can write down as a mixture of two distributions:
Here \(\delta\) is the Dirac delta function, i.e. the point mass distribution.
The C stdlib doesn't have a uniform random function so I wrote one (1) and used it to generate the data:
#include <stdlib.h>
/// get a float uniformly distributed on U[0, 1)
float frand() {
return (random() / (float) RAND_MAX);
}
arc4random(),
but I think the polynomial PRNG is good enough for this application,
and I like that we can use srandom(0) to force reproducibility.void synthesize(int n, long count, float X[n][count], float S_) {
// sparsity S in [0, 1), S_ is 1-S
for (long c = 0; c < count; c++) {
for (int i = 0; i < n; i++) {
if (frand() < S_) {
X[i][c] = frand();
}
}
}
}
Now we can generate some samples with sparsity 1-S = 0.1,
using a little printmat function (1) to check our work.
Below we see the result for four 5-D samples.
void printmat(char * tag, int rows, int cols, float A[rows][cols]) {
printf("%s: [\n", tag);
for (int m = 0; m < rows; m++) {
for (int n = 0; n < cols; n++) {
if (A[m][n]) {
printf(" %1.03f ", A[m][n]);
} else {
printf(" 0 ");
}
}
printf("\n");
}
printf("]\n");
}
const int count = 4;
srandom(0);
memset(X, 0, sizeof(X));
synthesize((float *) X, count, 0.1);
printmat("X", (float *) X, N, count);
Here we see that only ~2 of the 20 elements are non-zero, as expected with this sparsity level.
The model is a 2-layer feedforward network, where the hidden layer maps down from \(n=5\) to \(m=2\) dimensions without any activation function, and then the output layer uses the transpose of the hidden-layer weights plus a bias term and a ReLU activation function. This is, as far as I can tell, basically an autoencoder.
In matrix notation we have:
Breaking down into steps with indecies we have:
from which follows a first C implementation of the forward pass:
void forward(params_t * p, float x[N], float * y) {
float hk[M];
memset(hk, 0, sizeof(hk));
// hidden layer
for (int k = 0; k < M; k++) {
for (int i = 0; i < N; i++) {
hk[k] += p->W[k][i] * x[i];
}
}
// output layer
for (int j = 0; j < N; j++) {
y[j] += p->b[j];
for (int k = 0; k < M; k++) {
y[j] += p->W[k][j] * hk[k];
}
// ReLU activation
y[j] = y[j] > 0 ? y[j] : 0;
}
}
We want the model to prioritize representation of certain dimensions, so we assign an importance \(I_i\) to each dimension, which we make decrease geometrically: \(I_i = 0.7^i\). A weighted least-squares loss is then:
And our goal is to optimize the parameters \(W\) and \(b\) to minimize this loss. We then should be able to visualize the weights and see feature superposition emerging as a function of sparsity.
Note that in the paper they do not specify any regularization. I threw in the L2 regularization term because I saw that a weight-decay optimizer was used in the paper's code example on CoLab, but it turns out to be totally unnecessary if we pick the learning rate right.
As I'm a bit rusty on my calculus, I'll go step by step through the gradient computation. Taking the derivative with respect to an arbitrary weight and pushing the derivative inside the sums as far as it will go, applying the chain and power rules, and using \(\delta_j\) to denote the error in the \(j\)th output, we have:
Note that in the regularization term we've used the fact that the only summand that depends on \(w_{kj}\) is the one where \(k' = k\) and \(j' = j\), so the primes drop off the indices.
Now focusing on the derivative of the output layer, for the case where \(y_j\) is non-zero, we have:
Let's do an intuition check on this derivative. The weight \(w_{k i}\) appears in two places: once in the hidden layer as \(x_i\)'s contribution to \(h_k\), and once in the output layer as \(h_k\)'s contribution to \(y_j\). So increasing \(w_{k i}\) will increase the output proportionally to the value of \(h_k\), but then we need to add in the fact that \(h_k\) itself is also increased proportional to both the \(i\)th input and the current value of the weight. So our calculation seems intuitively correct.
To compute the gradient in C, we implement a gradient function that adds to a gradient accumulator:
The simplest way is just to take the forward pass and keep track of temporary variables that appear in the gradient expression above and then add them together as prescribed. For example the hidden layer computation now looks like:
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
wkj_xj[m][n] = p->W[m][n] * x[n];
hk[m] += wkj_xj[m][n];
}
}
And so on (1) as we compute the gradient, add to the accumulator, and return the loss.
float gradient(const params_t * p, const float x[N], float alpha, params_t * grad) {
// unlike the forward pass, we keep track of intermediate
// values that appear in the gradient
// our toy model is so small that all this fits comfortably
// in the thread stack
// alpha = L1 regularization coefficient
// grad is a pointer to the gradient accumulator
// returns loss
float wkj_xj[M][N];
float hk[M];
float y[N];
float delta[N];
float dL_wkj[M][N];
memset(wkj_xj, 0, sizeof(wkj_xj));
memset(hk, 0, sizeof(hk));
memset(y, 0, sizeof(y));
memset(delta, 0, sizeof(delta));
memset(dL_wkj, 0, sizeof(dL_wkj));
// hidden layer
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
wkj_xj[m][n] = p->W[m][n] * x[n];
hk[m] += wkj_xj[m][n];
}
}
// output layer
for (int n = 0; n < N; n++) {
for (int m = 0; m < M; m++) {
y[n] += p->W[m][n] * hk[m];
}
y[n] += p->b[n];
// ReLU activation
y[n] = y[n] > 0 ? y[n] : 0;
// compute delta
delta[n] = y[n] - x[n];
}
// compute error
float L = 0;
for (int n = 0; n < N; n++) {
float Ij = importance(n);
L += Ij * delta[n] * delta[n];
}
for (int n = 0; n < N; n++) {
for (int m = 0; m < M; m++) {
L += alpha * fabs(p->W[m][n]);
}
L += alpha * fabs(p->b[n]);
}
L /= 2;
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
if (y[n] <= 0) continue;
dL_wkj[m][n] = importance(n) * delta[n] * (hk[m] + wkj_xj[m][n])
+ alpha * (p->W[m][n] > 0 ? 1 : -1);
}
}
// add to gradient accumulator
for (int m = 0; m < M; m++) {
for (int n = 0; n < N; n++) {
grad->W[m][n] -= dL_wkj[m][n];
}
}
for (int n = 0; n < N; n++) {
if (y[n] <= 0) continue;
grad->b[n] -= delta[n] + alpha * (p->b[n] > 0 ? 1 : -1);
}
return L;
}
Now we put it all together (1), adding in a random batch of size 1024 which provides some stochasticity to the gradient descent. Note that I'm not using any optimizer, and I've got regularization turned off.
params_t p;
memset(&p, 0, sizeof(p));
// initialize with random weights and biases
for (int j = 0; j < N; j++) {
for (int k = 0; k < M; k++) {
p.W[k][j] = frand() * 0.001;
}
p.b[j] = frand() * 0.001;
}
params_t grad;
for (int r = 0; r < runs; r++) {
memset(&grad, 0, sizeof(grad));
float L = 0;
long batch[batch_size];
batch_indices(batch_size, batch);
for (long c = 0; c < batch_size; c++) {
L += gradient(&p, X[batch[c]], alpha, &grad);
}
update(&p, &grad, eta / batch_size);
printf("run: %d\n", r);
printf("L: %1.04f\n", L / batch_size);
if (r % 100 == 99) {
// print b
printmat("b", 1, N, p.b);
// print W
printmat("W", M, N, p.W);
// print grad w and b
printmat("grad w", M, N, grad.W);
printmat("grad b", 1, N, grad.b);
}
fflush(stdout);
}
This C program outputs a long log of the weights and loss during the training run. Runs take about 10 seconds for 10000 batches, which is enough to fully converge.
It took only a little bit of trial and error to get the learning rate right.
I then asked o3 (1) to take the outputted log and make an animation, resulting in the video shared at the top.
Here was the prompt that got me 90% of the way to a working animation:
Please write a Python program that takes a file called log with this format: (pasted example log snippet) and uses matplotlib to render loss as a function of the run, and the W matrix showing how each unit input vector is mapped to the hidden dimensions (2d) which should be a plot with one scatter dot for each of the 5 input unit vectors. Make this an animation showing how the points migrated over time, keeping the xy limits fixed so it is stable. Include a moving average of the loss as a line plot.
I'll close with an animation of the same model but with \(n=32\) features, and importance decaying as \(0.9^i\). Notice how it converges to a suboptimal solution!
You can see that the pentagon quickly forms out of features 0 through 4, and then features 5, 6, and 7 start to emerge, but then it is the less important feature 7 which pushes its way out to form a stable hexagon. Why is that? It seems to be because features 5 and 6 were unlucky enough to be on the side of the pentagon shared with higher-importance features while 7 had the good fortune of being near the relatively weaker feature 4 which it could push out of the way.
Bottom line: there are non-trivial local minima even in simple models and we can actually have some hope of gaining intuition about them.
Originally published on Memfault's Interrupt blog.
Persisting to flash is a necessary evil for many embedded devices. Let's take a look at some of the pitfalls and how they may be avoided.
In Manolo Martinez's recent talk at CUNY on the Rationalizing Role of Pains, he presented a model describing the decision-making process of a mind faced with multiple conflicting sensory messages of varying reliability. This model was by no means the focus of his talk, but it is what I'd like to focus on here.
One of the primary goals of contemporary neuroscience is the reverse-engineering of the brain's functional architecture. Our understanding has evolved from descriptive to functional, particularly through borrowing ideas from computer science and information theory. V. Balasubramanian and P. Sterling's paper explains several aspects of retinal design using information- and selection-theoretic arguments in conjunction with computer simulation.
Of the many machine learning models, the artificial neural network (ANN) is of particular interest because of the obvious analogy to the function of the brain. However, the standard supervised cost function and error back-propagation algorithm are entirely implausible from a biological perspective, and in practice the performance of back-prop decreases sharply with the number of hidden-layers, requiring more and more labeled training examples which are often in short supply.